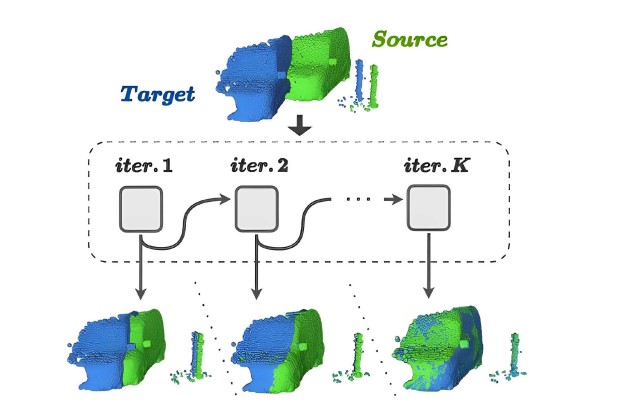
2024 | Authored by : Xiang, Xuezhi; Abdeen, Rokia; Li, Wei; El Saddik, Abdulmotaleb
{IEEE} Trans.
Intell.
Mach.
Pattern Anal.
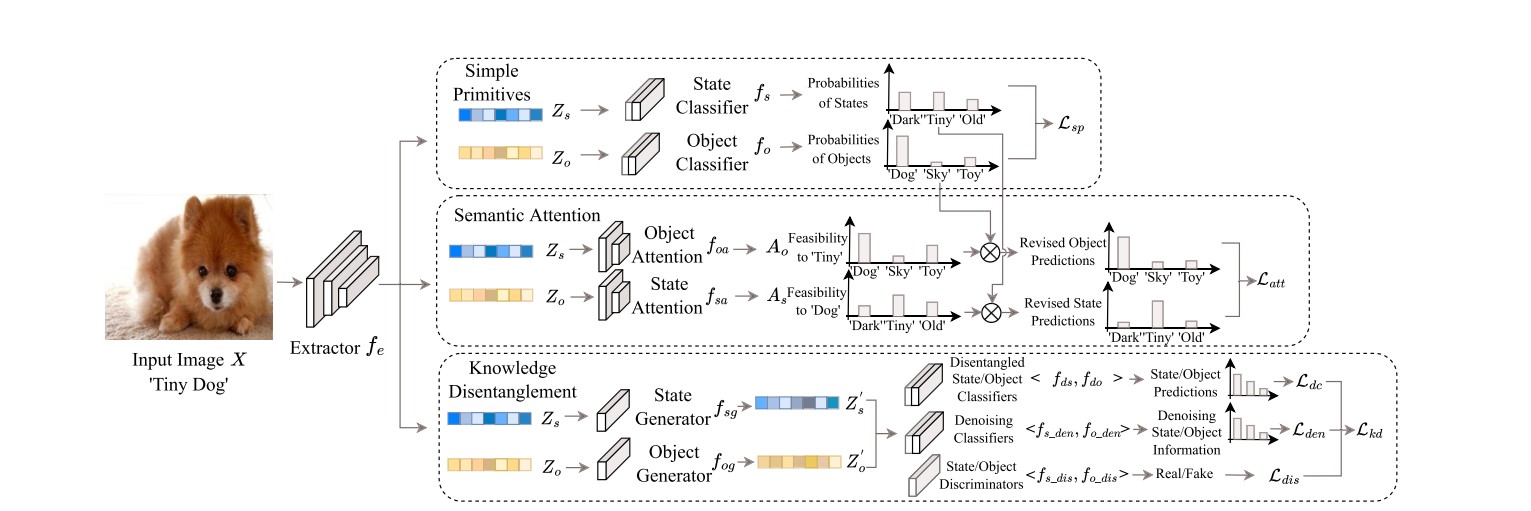
2024 | Authored by : Liu, Zhe; Li, Yun; Yao, Lina; Chang, Xiaojun; Fang, Wei; Wu, Xiaojun; El Saddik, Abdulmotaleb
{IEEE} Trans.
Intell.
Mach.
Pattern Anal.

2024 | Authored by : Xiang, Xuezhi; Abdeen, Rokia; Lv, Ning; El Saddik, Abdulmotaleb
Pattern Recognit.

2024 | Authored by : Chen, Ying; Yao, Rui; Zhou, Yong; Zhao, Jiaqi; Liu, Bing; El Saddik, Abdulmotaleb
{ACM} Trans.
Appl.
Commun.
Comput.
Multim.

2023 | Authored by : Al Zamzami, Fatimah; El Saddik, Abdulmotaleb
CoRR

2023 | Authored by : Al Zamzami, Fatimah; El Saddik, Abdulmotaleb
CoRR
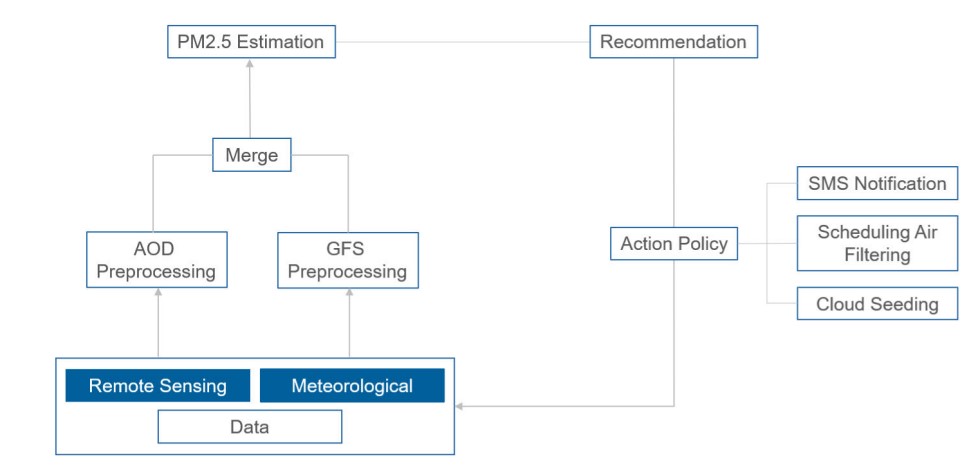
2023 | Authored by : Abutalip, Kudaibergen; Al{-}Lahham, Anas; El Saddik, Abdulmotaleb
{IEEE} Access

2023 | Authored by : Zhao, Jiaqi; Ding, Zeyu; Zhou, Yong; Zhu, Hancheng; Du, Wenliang; Yao, Rui; El Saddik, Abdulmotaleb
CoRR
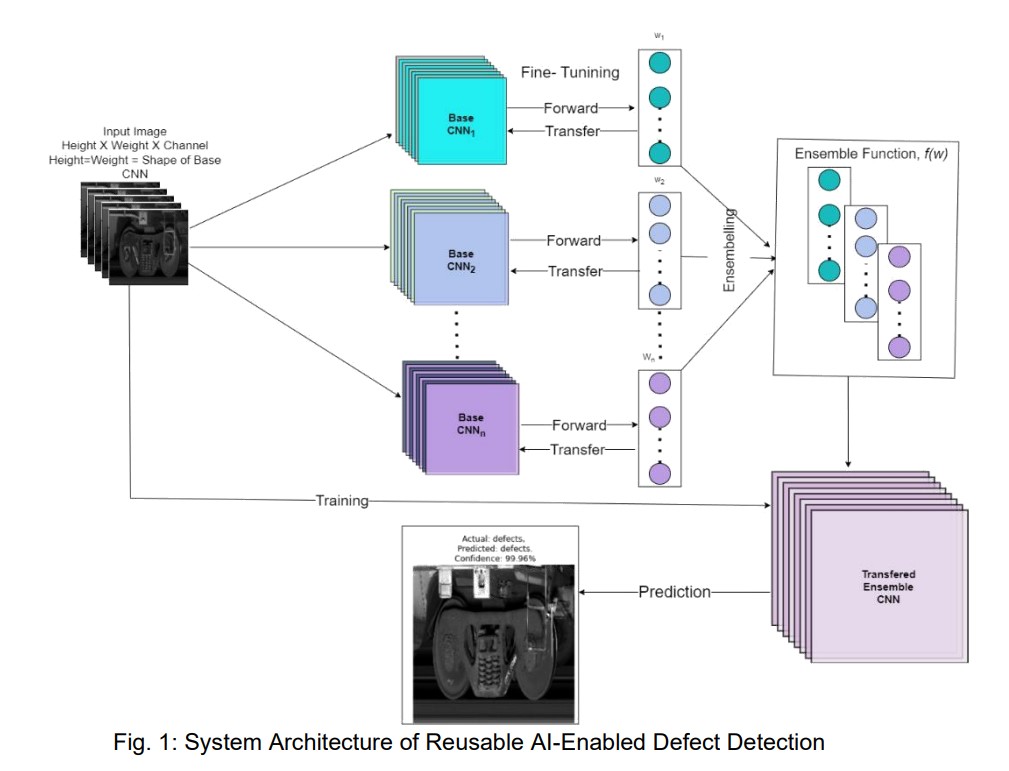
2023 | Authored by : Ferdousi, Rahatara; Laamarti, Fedwa; Yang, Chunsheng; El Saddik, Abdulmotaleb
CoRR

2023 | Authored by : Ferdousi, Rahatara; Faisal, Mohammed; Laamarti, Fedwa; Yang, Chunsheng; El Saddik, Abdulmotaleb
CoRR
2023 | Authored by : Al Zamzami, Fatimah; El Saddik, Abdulmotaleb
{IEEE} Access
2023 | Authored by : Azzuni, Hussam; Jamal, Sharim; El saddik, Abdulmotaleb
CoRR
2023 | Authored by : Ali, Eman; Guan, Dayan; Lu, Shijian; El saddik, Abdulmotaleb
CoRR
2023 | Authored by : Al{-}Zamzami, Fatimah; El Saddik, Abdulmotaleb
CoRR
2023 | Authored by : Wang, Zhi Qiang; El Saddik, Abdulmotaleb
{IEEE} Access
2023 | Authored by : Zhou, Chenyu; Chen, Hongzhou; Wang, Shiman; Sun, Xinyao; El Saddik, Abdulmotaleb; Cai, Wei
CoRR

2023 | Authored by : Abilkaiyrkyzy, Akbobek; Elhagry, Ahmed; Laamarti, Fedwa; El Saddik, Abdulmotaleb
{IEEE} Access

2023 | Authored by : Zhu, Jiayi; Qin, Xuebin; El saddik, Abdulmotaleb
CoRR
2023 | Authored by : Liu, Kunhao; Zhan, Fangneng; Zhang, Jiahui; Xu, Muyu; Yu, Yingchen; El Saddik, Abdulmotaleb; Theobalt, Christian; Xing, Eric P.; Lu, Shijian
CoRR

2023 | Authored by : Ghaboura, Sara; Ferdousi, Rahatara; Laamarti, Fedwa; Yang, Chunsheng; El Saddik, Abdulmotaleb
{IEEE} Access
2023 | Authored by : Abutalip, Kudaibergen; Saeed, Numan; Khan, Mustaqeem; El Saddik, Abdulmotaleb
CoRR

2023 | Authored by : Xiao, Aoran; Huang, Jiaxing; Xuan, Weihao; Ren, Ruijie; Liu, Kangcheng; Guan, Dayan; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
CoRR

2023 | Authored by : Liu, Kunhao; Zhan, Fangneng; Chen, Yiwen; Zhang, Jiahui; Yu, Yingchen; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
CoRR
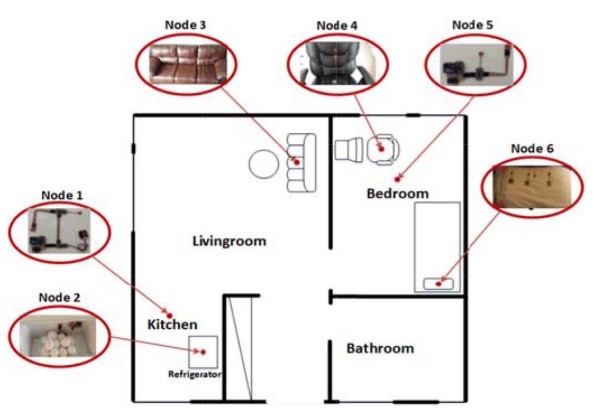
2023 | Authored by : Hafidh, Basim; Osman, Hussein Al; Dong, Haiwei; El Saddik, Abdulmotaleb
CoRR
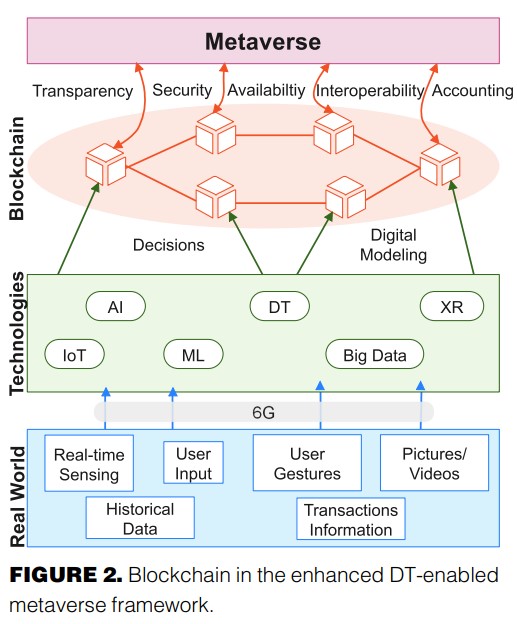
2023 | Authored by : Aloqaily, Moayad; Bouachir, Ouns; Karray, Fakhri; Ridhawi, Ismaeel Al; El Saddik, Abdulmotaleb
{IEEE} Consumer Electron.
Mag.
2023 | Authored by : Yang, Lin; Yang, Bowen; Dong, Haiwei; El Saddik, Abdulmotaleb
CoRR

2023 | Authored by : Hossain, M. Shamim; Bilbao, Josu; Tobn, Diana P.; El Saddik, Abdulmotaleb
Computing

2023 | Authored by : Lv, Ning; Xiang, Xuezhi; Wang, Xinyao; Qiao, Yulong; El Saddik, Abdulmotaleb
Comput.
Image Underst.
Vis.

2023 | Authored by : El Saddik, Abdulmotaleb
{IEEE} Intern.
{MIPR}
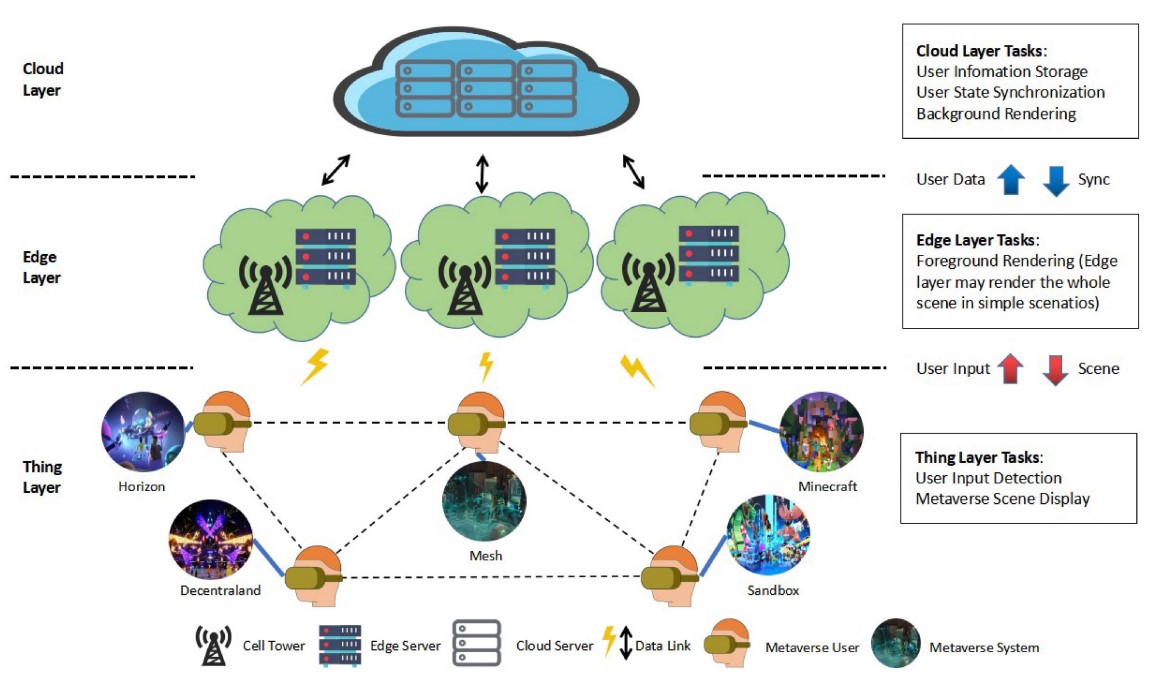
2023 | Authored by : Long, Zijian; Dong, Haiwei; El Saddik, Abdulmotaleb
IEEE
Internet
Things J

2023 | Authored by : Zhao, Jiaqi; Wang, Hanzheng; Zhou, Yong; Yao, Rui; Zhang, Lixu; El Saddik, Abdulmotaleb
Comput.
Image Vis.
2023 | Authored by : Mumtaz, Shahid; Cherkaoui, Soumaya; Guizani, Mohsen; Rodrigues, Joel J. P. C.; El Saddik, Abdulmotaleb; Maharjan, Sabita; Xiao, Yang; Ashraf, Ikram
{IEEE} J.
Sel. Areas Commun.

2023 | Authored by : Xiang, Xuezhi; Zhang, Kaixu; Qiao, Yulong; El Saddik, Abdulmotaleb
Image Represent.
J. Vis. Commun.
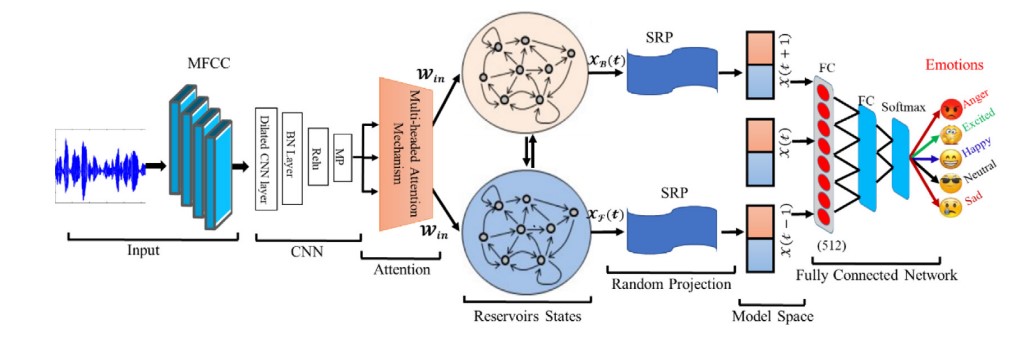
2023 | Authored by : Khan, Mustaqeem; El Saddik, Abdulmotaleb; Alotaibi, Fahd Saleh; Pham, Nhat Truong
Based Syst.
Knowl.
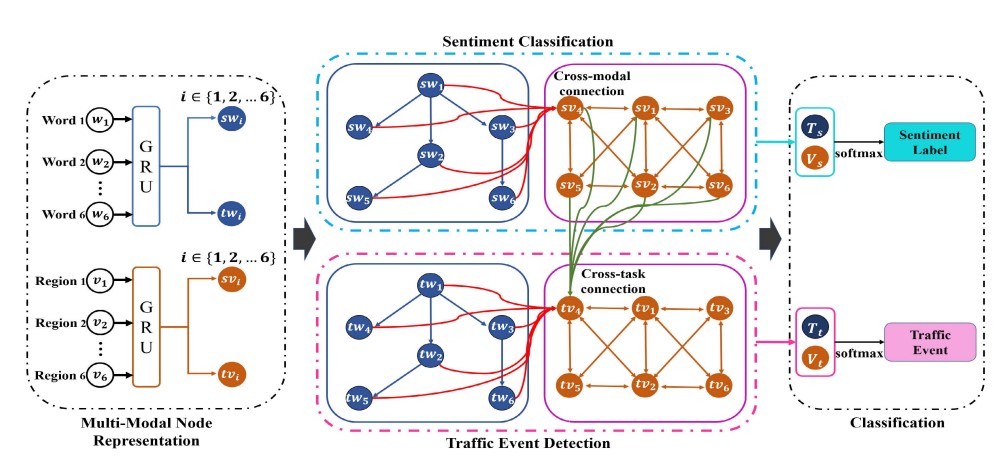
2023 | Authored by : Zhang, Yazhou; Tiwari, Prayag; Zheng, Qian; El Saddik, Abdulmotaleb; Hossain, M. Shamim
{IEEE} Trans.
Intell.
Syst.
Transp.

2023 | Authored by : Zhao, Jiaqi; Wang, Hanzheng; Zhou, Yong; Yao, Rui; Chen, Silin; El Saddik, Abdulmotaleb
{IEEE} Trans.
Multim.
2023 | Authored by : Liu, Hao; Yan, Zhaoyu; Liu, Bing; Zhao, Jiaqi; Zhou, Yong; El Saddik, Abdulmotaleb
{ACM} Trans.
Appl.
Comput. Commun.
Multim.
2023 | Authored by : Zhou, Chenyu; Chen, Hongzhou; Wang, Shiman; Sun, Xinyao; El Saddik, Abdulmotaleb; Cai, Wei
{IEEE} Wirel.
Commun.
2023 | Authored by : Liu, Kunhao; Zhan, Fangneng; Chen, Yiwen; Zhang, Jiahui; Yu, Yingchen; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
{CVPR} 2023
{IEEE/CVF} Conference on Computer Vision and Pattern Recognition
BC
Canada
Vancouver
2023 | Authored by : Xiao, Aoran; Huang, Jiaxing; Xuan, Weihao; Ren, Ruijie; Liu, Kangcheng; Guan, Dayan; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
{CVPR} 2023
{IEEE/CVF} Conference on Computer Vision and Pattern Recognition
BC
Canada
Vancouver

2023 | Authored by : Gasseller, M.; El Saddik, Abdulmotaleb; Brooks, D.; Sunda Meya, Anderson; Khawli, Toufik Al; Islam, S.
{I2MTC} 2023
{IEEE} International Instrumentation and Measurement Technology Conference
Kuala Lumpur
Malaysia
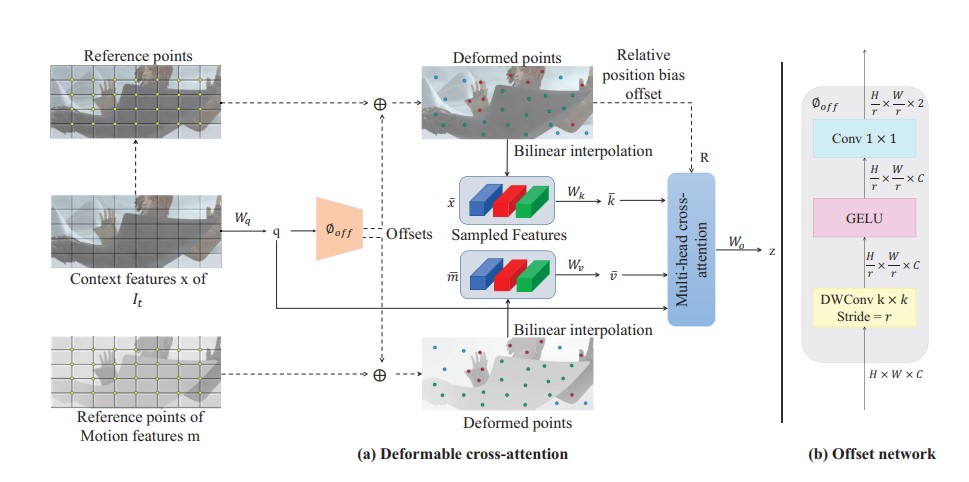
2023 | Authored by : Abdeen, Rokia; Xiang, Xuezhi; Lv, Ning; El Saddik, Abdulmotaleb
{IEEE} International Conference on Acoustics
Greece
Rhodes Island
Speech and Signal Processing {ICASSP} 2023
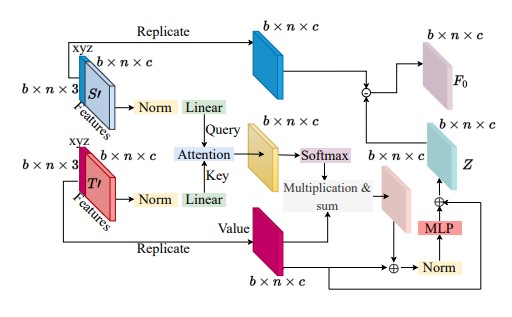
2023 | Authored by : Abdeen, Rokia; Xiang, Xuezhi; El Saddik, Abdulmotaleb
{ICIP} 2023
{IEEE} International Conference on Image Processing
Kuala Lumpur
Malaysia

2023 | Authored by : Elhagry, Ahmed; Dai, Hang; El Saddik, Abdulmotaleb; Gueaieb, Wail; Masi, Giulia De
{ICRA} 2023
{IEEE} International Conference on Robotics and Automation
London
UK
2023 | Authored by : Elhagry, Ahmed; Dai, Hang; El Saddik, Abdulmotaleb
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
2023 | Authored by : Zhou, Chenyu; Chen, Hongzhou; Wang, Shiman; Sun, Xinyao; El Saddik, Abdulmotaleb; Cai, Wei
{IEEE} Wirel.
Commun.

2023 | Authored by : Liu, Kunhao; Zhan, Fangneng; Chen, Yiwen; Zhang, Jiahui; Yu, Yingchen; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
{CVPR} 2023
{IEEE/CVF} Conference on Computer Vision and Pattern Recognition
BC
Canada
Vancouver

2023 | Authored by : Xiao, Aoran; Huang, Jiaxing; Xuan, Weihao; Ren, Ruijie; Liu, Kangcheng; Guan, Dayan; El Saddik, Abdulmotaleb; Lu, Shijian; Xing, Eric P.
{CVPR} 2023
{IEEE/CVF} Conference on Computer Vision and Pattern Recognition
BC
Canada
Vancouver

2023 | Authored by : Gasseller, M.; El Saddik, Abdulmotaleb; Brooks, D.; Sunda Meya, Anderson; Khawli, Toufik Al; Islam, S.
{I2MTC} 2023
{IEEE} International Instrumentation and Measurement Technology Conference
Kuala Lumpur
Malaysia
2023 | Authored by : Abdeen, Rokia; Xiang, Xuezhi; Lv, Ning; El Saddik, Abdulmotaleb
{IEEE} International Conference on Acoustics
Greece
Rhodes Island
Speech and Signal Processing {ICASSP} 2023
2023 | Authored by : Abdeen, Rokia; Xiang, Xuezhi; El Saddik, Abdulmotaleb
{ICIP} 2023
{IEEE} International Conference on Image Processing
Kuala Lumpur
Malaysia

2023 | Authored by : Elhagry, Ahmed; Dai, Hang; El Saddik, Abdulmotaleb; Gueaieb, Wail; Masi, Giulia De
{ICRA} 2023
{IEEE} International Conference on Robotics and Automation
London
UK
2023 | Authored by : Elhagry, Ahmed; Dai, Hang; El Saddik, Abdulmotaleb
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
2023 | Authored by : Khan, Mustaqeem; Gueaieb, Wail; El Saddik, Abdulmotaleb; Masi, Giulia De; Karray, Fakhri
{IEEE} International Smart Cities Conference
{ISC2} 2023
Bucharest
Romania

2023 | Authored by : Khan, Abbas; Khan, Mustaqeem; Gueaieb, Wail; El Saddik, Abdulmotaleb; Masi, Guilia De; Karray, Fakhri
{IEEE} International Smart Cities Conference
{ISC2} 2023
Bucharest
Romania
2023 | Authored by : Saad, Muhammad; Khan, Mustaqeem; Saeed, Muhammad; El Saddik, Abdulmotaleb; Gueaieb, Wail
{IEEE} International Smart Cities Conference
{ISC2} 2023
Bucharest
Romania
2023 | Authored by : Saeed, Muhammad; Khan, Abbas; Khan, Mustaqeem; Saad, Muhammad; El Saddik, Abdulmotaleb; Gueaieb, Wail
{IEEE} International Smart Cities Conference
{ISC2} 2023
Bucharest
Romania
2023 | Authored by : Khan, Mustaqeem; Saeed, Muhammad; El Saddik, Abdulmotaleb; Gueaieb, Wail
{ISIE} 2023
32nd {IEEE} International Symposium on Industrial Electronics
Finland
Helsinki
2023 | Authored by : Khan, Ufaq; Khan, Mustaqeem; El Saddik, Abdulmotaleb; Gueaieb, Wail
{IEEE} International Symposium on Medical Measurements and Applications
Jeju
Korea
MeMeA 2023
Republic of
2023 | Authored by : Kharrat, Farah; Gueaieb, Wail; Karray, Fakhri; El Saddik, Abdulmotaleb
{IEEE} International Symposium on Medical Measurements and Applications
Jeju
Korea
MeMeA 2023
Republic of

2021 | Authored by : Jiaman Li, Ruben Villegas, Duygu Ceylan, Jimei Yang, Zhengfei Kuang, Hao Li, Yajie Zhao


2021 | Authored by : Tianye Li, Shichen Liu, Timo Bolkart, Jiayi Liu, Hao Li, Yajie Zhao

2021 | Authored by : Huiwen Luo, Liwen Hu, Koki Nagano, Zejian Wang, Han-Wei Kung, Qingguo Xu, Lingyu Wei, Hao Li

2021 | Authored by : Huiwen Luo, Liwen Hu, Koki Nagano, Zejian Wang, Han-Wei Kung, Qingguo Xu, Lingyu Wei, Hao Li
2021 | Authored by : Haiwei Chen, Shichen Liu, Weikai Chen, Hao Li


2020 | Authored by : Ruilong Li, Yuliang Xiu, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li

2020 | Authored by : Jiaman Li, Zhengfei Kuang, Yajie Zhao, Mingming He, Karl Bladin, Hao Li
2020 | Authored by : Yi Zhou, Chenglei Wu, Zimo Li, Chen Cao, Yuting Ye, Jason Saragih, Hao Li, Yaser Sheikh
2020 | Authored by : Ruilong Li, Karl Bladin, Yajie Zhao, Chinmay Chinara, Owen Ingraham, Pengda Xiang, Xinglei Ren, Pratusha Prasad, Biping Kishore, Jun Xing, Hao Li

2020 | Authored by : Kyle Olszewski, Duygu Ceylan, Jun Xing, Jose I. Echevarria, Zhili Chen, Weikai Chen, Hao Li

2020 | Authored by : Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, Tony Tung

2020 | Authored by : Hao Li, Jaewoo Seo, Koki Nagano, McLean Goldwhite, Huiwen Luo, Zejian Wang, Lingyu Wei, Yen-Chun Chen

2020 | Authored by : Ruilong Li, Yuliang Xiu, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li

2020 | Authored by : Zejian Wang, Koki Nagano, Liwen Hu, McLean Goldwhite, Jaewoo Seo, Qingguo Xu, Huiwen Luo, Hanwei Kung, Aviral Agarwal, Yen-Chun Chen, Lingyu Wei, Hao Li
2019 | Authored by : Shichen Liu, Shunsuke Saito, Weikai Chen, Hao Li

2019 | Authored by : Koki Nagano, Huiwen Luo, Zejian Wang, Jaewoo Seo, Jun Xing, Liwen Hu, Lingyu Wei, Hao Li


2019 | Authored by : Yajie Zhao, Zeng Huang, Tianye Li, Weikai Chen, Chloe LeGendre, Xinglei Ren, Jun Xing, Ari Shapiro, Hao Li

2019 | Authored by : Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, Hao Li



2019 | Authored by : Ryota Natsume, Shunsuke Saito, Zeng Huang, Weikai Chen, Chongyang Ma, Hao Li, Shigeo Morishima
2019 | Authored by : Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, Hao Li

2019 | Authored by : Hao Li, Jaewoo Seo, Koki Nagano, Zejian Wang, Liwen Hu, Lingyu Wei, Yen-Chun Chen


2019 | Authored by : Hao Li, Juan Miguel de Joya, Tianxiang Zheng, Sergey Demyanov, Noelle Martin, Alain Chesnais, Koki Nagano, Bill Posters, Per Karlsson, Taylor Beck, Alexandre de Brébisson, Jassim Happa

2019 | Authored by : Hao Li, Koki Nagano, Kyle San, McLean Goldwhite, Kyle San, Jaewoo Seo, Yen-Chun Chen, Marco Fratarcangeli






2018 | Authored by : Yuhang Song, Chao Yang, Zhe Lin, Xiaofeng Liu, Qin Huang, Hao Li, C.-C. Jay Kuo

2018 | Authored by : Shugo Yamaguchi, Shunsuke Saito, Koki Nagano, Yajie Zhao, Weikai Chen, Kyle Olszewski, Shigeo Morishima, Hao Li


2018 | Authored by : Chris Bregler, Alyosha Efros, Irfan Essa, Hany Farid, Ira Kemelmacher-Schlizerman, Matthias Nießner, Luisa Verdoliva, Hao Li

2018 | Authored by : Koki Nagano, Jaewoo Seo, Jun Xing, Kyle San, Aaron Hong, Mclean Goldwhite, Jiale Kuang, Aviral Agarwal, Caleb Arthur, Hanwei Kung, Stuti Rastogi, Carrie Sun, Stephen Chen, Jens Fursund, Hao Li


2017 | Authored by : Tianye Li, Timo Bolkart, Michael J. Black, Hao Li, Javier Romero

2017 | Authored by : Ronald Yu, Shunsuke Saito, Haoxiang Li, Duygu Ceylan, Hao Li
2017 | Authored by : Kyle Olszewski, Zimo Li, Chao Yang, Yi Zhou, Ronald Yu, Zeng Huang, Sitao Xiang, Shunsuke Saito, Pushmeet Kohli, Hao Li

2017 | Authored by : Julian Zilly, Amit Boyarski, Micael Carvalho, Amir Atapour Abarghouei, Konstantinos Amplianitis, Aleksandr Krasnov, Massimiliano Mancini, Hernán Gonzalez, Riccardo Spezialetti, Carlos Sampredo Pérez, Hao Li

2017 | Authored by : Shunsuke Saito, Lingyu Wei, Liwen Hu, Koki Nagano, Hao Li

2017 | Authored by : Sema Berkiten, Maciej Halber, Justin Solomon, Chongyang Ma, Hao Li, Szymon Rusinkiewicz





2016 | Authored by : Kyle Olszewski, Joseph J. Lim, Shunsuke Saito, Hao Li



2016 | Authored by : Hao Li, Shunsuke Saito, Jens Fursund, Lingyu Wei, Chao Yang, Ronald Yu, Stephen Chen, Isabella Benavente, Yen-Chun Chen

2016 | Authored by : Jonathan Masci, Emanuelle Rodolà, Davide Boscaini, Michael M. Bronstein, Hao Li


2016 | Authored by : Hao Li, Anshuman Das, Tristan Swedish, Pratik Shah, Lingyu Wei, Ramesh Raskar
2015 | Authored by : Vikas Khanduja, Nick Baelde, Andreas Dobbelaere, Jan Van Houcke, Hao Li, Christophe Pattyn, Emmanuel A. Audenaert

2015 | Authored by : Christian Sandor, Martin Fuchs, Alvaro Cassinelli, Hao Li, Richard Newcombe, Goshiro Yamamoto, Steven Feiner









2014 | Authored by : Javier von der Pahlen, Jorge Jimenez, Etienne Danvoye, Paul Debevec, Graham Fyffe, Hao Li

2014 | Authored by : Ari Shapiro, Andrew Feng, Ruizhe Wang, Hao Li, Mark Bolas, Gerard Medioni, Evan Suma


2014 | Authored by : Ari Shapiro, Andrew Feng, Ruizhe Wang, Hao Li, Mark Bolas, Gerard Medioni, Evan Suma


2013 | Authored by : Hao Li, Etienne Vouga, Anton Gudym, Jonathan T. Barron, Linjie Luo, Gleb Gusev



2011 | Authored by : Thibaut Weise, Sofien Bouaziz, Hao Li, Mark Pauly

2011 | Authored by : Thibaut Weise, Sofien Bouaziz, Hao Li, Mark Pauly











